-
要點
ChatGPT是什么?它會對經濟、生活、金融產生哪些影響?
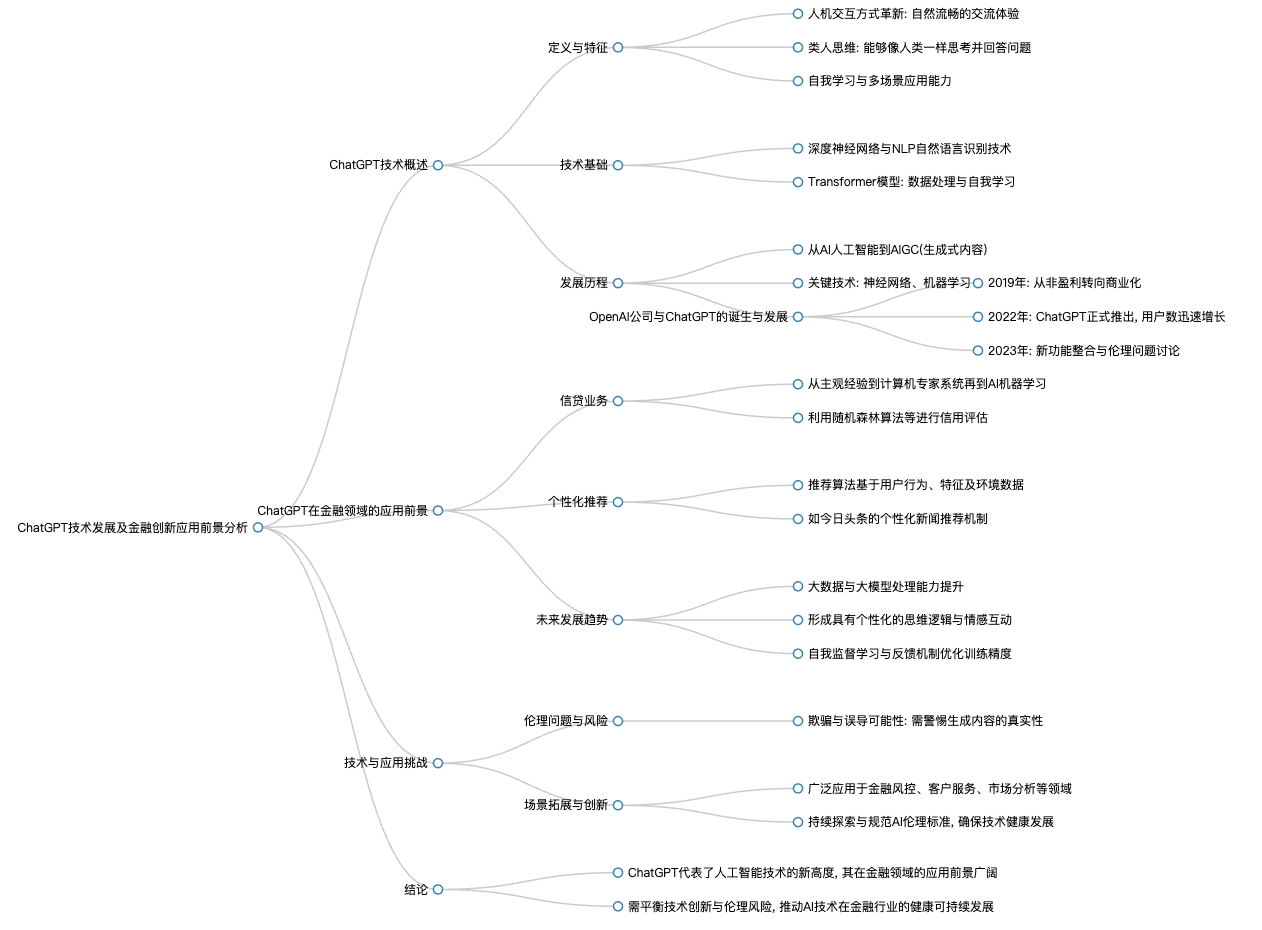
ChatGPT是一種人機交互方式,提供了自然式的交流體驗,并具備類人思維,能像人一樣思考和回答問題。它將對經濟、生活和金融產生深遠影響,例如通過高效的信息檢索與分析能力,幫助人們快速找到問題的答案,改變傳統的信息獲取和處理方式。
-
要點
ChatGPT如何通過電影《貧民窟的百萬富翁》中的情節來展示其信息處理能力?
在電影《貧民窟的百萬富翁》中,角色杰瑪馬利克能夠迅速解答各種問題,這體現了ChatGPT般的信息檢索和判斷能力,即在分析問題時能快速調閱大腦中的知識庫、信息庫以找到準確答案。
-
要點
ChatGPT在藝術創作中的應用是怎樣的?
ChatGPT可以用于繪畫創作,通過用戶提供的關鍵詞或檢索詞生成相應的畫作。例如,當給出描述牡丹花的詳細關鍵詞后,ChatGPT能夠生成絢爛多姿的畫作,這展示了其根據用戶需求進行成果輸出的能力,而這一過程依賴于大量信息輸入和大數據模型(如transformer)的運算。
-
要點
ChatGPT技術發展的前世今生及其在金融領域的未來發展是怎樣的?
ChatGPT技術起源于2022年,由OpenAI公司開發,是一種對話式的機器人模型,具有回答問題、承認錯誤、挑戰錯誤前提以及拒絕非法要求等類人思維特征。隨著GPT-4的推出,其能力進一步增強,能夠理解上下文規則、內容特點,并遵循開發者的指令進行工作。在金融領域,ChatGPT未來有望應用于金融數據分析、風險評估、智能投顧等方面,提升金融服務效率和質量。
-
要點
GPT s新產品主要有哪些特點?
GPT s新產品具有兩大特點,一是能夠自我學習,二是能夠多場景應用。用戶無需懂程序代碼,只需輸入自己的需求和素材,如審計、金融服務、營銷等內容,系統會通過transformer大模型進行運算,生成用戶所需的結果。
-
要點
ChatGPT技術的基礎是什么?ChatGPT的發展歷程是怎樣的?
ChatGPT技術基于AI人工智能,是一種交互式的聊天機器人,擁有強大的語言理解和自我學習能力。它利用NLP自然語言識別技術對大量素材、語料、知識信息進行學習,并采用深度神經網絡和NLP自然語言識別技術來支撐其發展。ChatGPT的發展經歷了從馬車時代到現今智能汽車時代的各個階段,背后推動發展的就是人工智能技術。其中,ChatGPT作為AI人工智能發展的基礎和平臺,其發展離不開算力提升和神經網絡學習能力的進步。
-
要點
ChatGPT的大模型(transformer)主要用途和特性有哪些?
transformer大模型主要用于數據處理和加工,具有自我學習和多場景應用的特點。它能實現流暢的內容生成和便捷對話,且應用場景廣泛,能較好地理解語義并準確回答問題。此外,ChatGPT采用了基于人類反饋的獎勵機制,將用戶的點贊和評價作為二次學習的參數,以優化輸出結果。
-
要點
AIGC是什么概念,以及它如何與ChatGPT相關聯?神經網絡在ChatGPT中的作用是什么?
AIGC(Artificial Intelligence Generated Content)是指人工智能生成式內容,它允許用戶根據需求讓計算機創造文章、程序等各種形式的內容,這在傳統交互過程中無法實現。ChatGPT的誕生賦予了AI靈魂,成為了實現AIGC的基礎和平臺。神經網絡在ChatGPT中扮演著信息輸入、加工、分析、儲存以及特征識別的角色。通過注意力機制融入神經網絡,形成transformer模型,使得系統能關注關鍵信息并進行高效運算。最后,輸出層(output layer)將經過處理的信息以多種形式輸出,如文字、程序、繪畫等,從而實現了多樣化的生成內容。
-
要點
機器學習主要分為哪兩種學習模式?監督學習的工作原理是什么?
機器學習主要分為監督學習和無監督學習兩種模式。監督學習是通過給機器學習模型提供已知標簽的數據(如花、馬、汽車等),讓機器學習其特征,并在面對新數據時通過比較得出相似度和擬合度的結果。
-
要點
機器學習中的學習方式有哪些?
機器學習中的學習方式包括監督學習、半監督學習、無監督學習和自監督學習。其中,監督學習是一對一學習,而自監督學習具有創新性和思考性,能夠自我學習并思考數據間的關聯關系。
-
要點
無監督學習的重點是什么?
無監督學習更側重于發現數據點之間的內在關聯關系,即“物以類聚,人以群分”,這是它與監督學習的主要區別。
-
要點
深度學習的作用是什么?
深度學習主要用于處理非線性關系的數據,通過多層非線性變換結構抽象出復雜模型,是模擬人腦識別、運算和分級分類抽象化過程的一種算法,也是transformer模型計算的基礎。
-
要點
ChatGPT的本質是什么?
ChatGPT全名chat generate pretrained transformer,是一種由OpenAI開發的大規模語言模型,基于預先訓練的模型(per-train model),通過學習大量數據形成語料庫,進而能夠生成與人類自然語言交互的內容。
-
要點
ChatGPT的發展歷程中有哪些關鍵事件和人物?
ChatGPT的發展歷程中有多個關鍵事件,例如從非盈利組織過渡到商業化機構、與微軟進行深度合作、發布首個商業產品以及形成ChatGPT基礎模型等。馬斯克在其中發揮了重要作用,聯合多家機構共同推進ChatGPT的發展。
-
要點
ChatGPT在深化學習過程中可能出現什么倫理問題?
隨著ChatGPT的不斷深化學習,可能會出現欺騙的倫理問題,即生成的內容可能在加工過程中有意識或無意識地產生誤導現象,甚至在面對極大壓力時,內容可能是虛假的,這已在學術界和金融界有所發現。
-
要點
ChatGPT可以在哪些領域深度應用,并結合業務的方法有哪些?
ChatGPT可以在信貸業務中應用,通過模仿人類決策過程中的經驗與準則,逐步發展到利用機器學習AI進行數據點之間的關系和非線性聯系的自我學習,形成如隨機森林算法等模型,通過訓練集和測試集來判斷新數據樣本的風險等級。
-
要點
推薦算法的工作原理是什么?頭條號推薦算法有何特色?
推薦算法基于決策性AI技術,收集用戶的行為數據、留痕數據、特征數據及個性化數據,經過大數據計算后向用戶和商戶推送用戶可能關注的信息。例如,手機應用會根據用戶偏好推送電影、新聞等推薦內容。頭條號推薦算法融合了三大類內容:新聞內容、用戶特性(如點擊、瀏覽、轉發、收藏的操作對應年齡、習慣、職業等特征)以及環境特征(工作場合、通勤狀態、旅游線路等)。通過采集這些信息偏好,進行大數據分析以預估特定場景下內容對用戶的適合度。
-
要點
ChatGPT未來發展的趨勢和應用場景有哪些?
未來ChatGPT的應用場景將更加廣泛,它將結合大數據、大模型處理技術,發展出AIGC和TGBT訓練邏輯和模型,形成個性化思維邏輯,實現與用戶之間的情感互動和交流。ChatGPT將通過自我反饋、自我修正的學習過程提升訓練精度和信息內容的廣度深度,使其應用場景日益豐富。







 關鍵詞
關鍵詞
 全文摘要
全文摘要
 章節速覽
章節速覽




 機構學苑
機構學苑




