電話:400-9955-880






該課程在您的購物車中

該課程在您的待付款訂單中

您已購買該課程
尊敬的會員:
歡迎回到金庫網這一全國理財師的網上家園。2021年11月10日,您加入了金庫網的會員大家庭,獲得了上千門精彩好課的暢學權益,并享有直播課免費參加的特權。

 機構學苑
機構學苑


 關鍵詞
關鍵詞
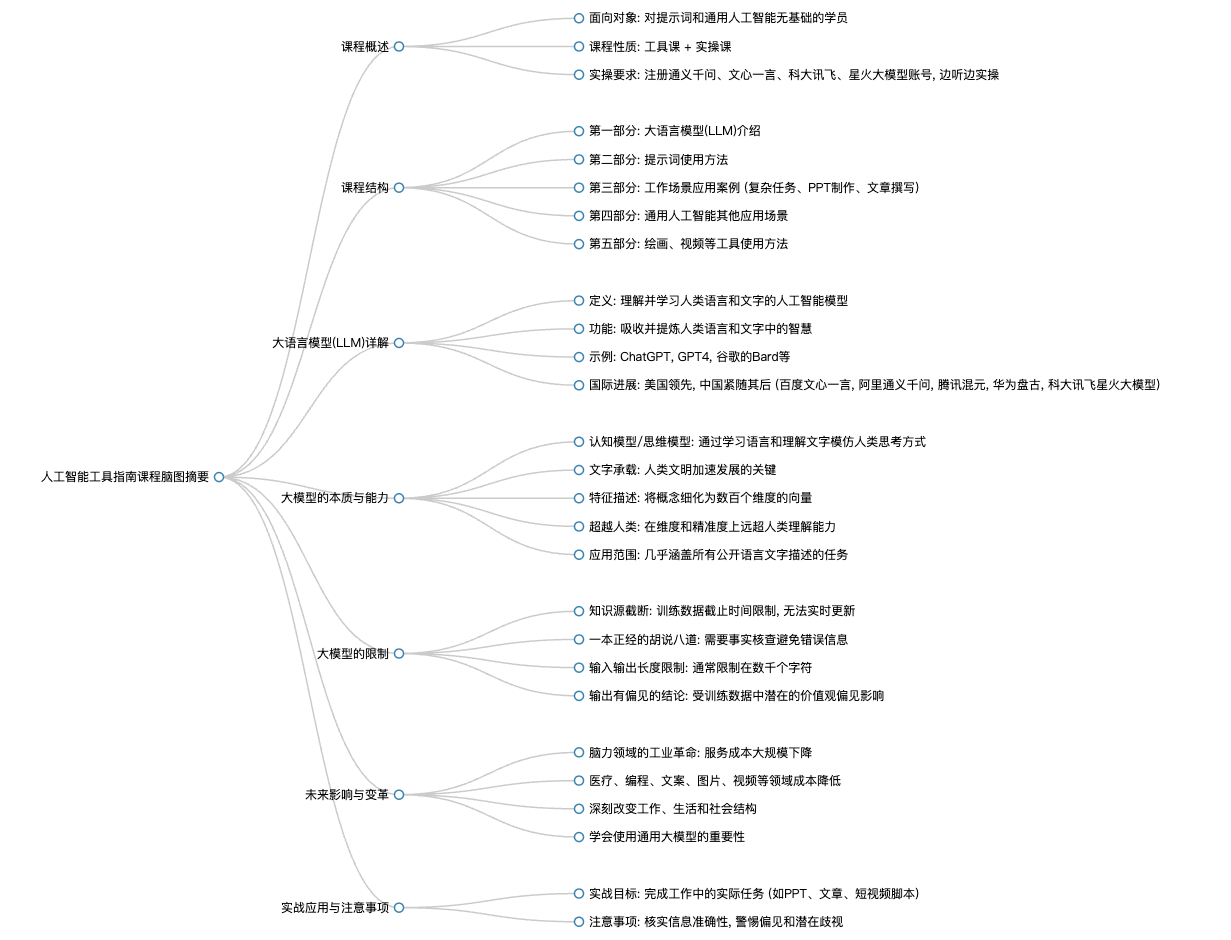
 全文摘要
全文摘要
 章節(jié)速覽
章節(jié)速覽